Presentación de gbTeXpublisher
Sumario
gbTeXpublisher es una aplicación diseñada para facilitar la producción editorial. Si te desempeñas como editor, corrector o diseñador de libros, especialmente con un enfoque significativo en la edición científica, este artículo introductorio podría resultarte de interés.
gbTeXpublisher nace como resultado de una necesidad concreta –mi producción editorial–, desde hace bastante tiempo adhiero al modelo de producción de edición ramificada y encuentro en LaTeX la vía apropiada para conseguirlo, hice varios intentos con markdown y asciidoc, pero al final del recorrido siempre encontraba problemas, fundamentalmente en la salida a PDF, me estoy refiriendo a una salida con un alto estándar de calidad tipográfica.
gbTeXpublisher es una aplicación de escritorio que permite gestionar de manera fácil los procesos de producción editorial basados en el lenguaje LaTeX, me gusta pensar en esta aplicación como un facilitador, ya que todo lo que se puede hacer con gbTeXpublisher, también se puede hacer sin gbTeXpublisher, la diferencia radica en la facilidad que otorga su interfaz.
gbTeXpublisher es también el resultado del enorme trabajo de muchas personas, a todas les estoy agradecido, pero quisiera hacer una mención particular para Donald Knuth, Benoît Minisini y los foros de CervanTeX y Gambas y, de manera especial, para Michal Hoftich, ya que el aporte de su desarrollo ha sido clave en el rumbo que tomaron mis decisiones de producción.
Dejo por último a Alejandro Moyano, Sergio Santamaría y Ramiro Santa Ana Anguiano, sus comentarios y aportes fueron de gran ayuda en el desarrollo de este proyecto.
gbTeXpublisher posee licencia GPL3, por consiguiente se concede permiso para copiar, distribuir y modificar este software según los términos de dicha licencia.
Este artículo es un intento de presentación formal (aunque considero que el desarrollo se encuentra en beta) y me parece oportuno comenzar con una corta introducción teórica sobre los modelos de producción editorial al día de hoy.
Pequeña introducción
Es evidente que desde la década de los noventa, la edición se ha vuelto completamente digital. Esto se refleja en la adopción generalizada de sistemas informáticos por parte de los diferentes actores involucrados en el proceso editorial, quienes utilizan estas tecnologías para escribir, editar, imprimir y distribuir. Un ejemplo notable es que las imprentas hoy en día solo aceptan trabajos en formato digital.
A pesar de esta transformación digital, me aventuro a sugerir que la tradición editorial no ha logrado, o quizás no ha sabido, asimilar que estos cambios no se limitan simplemente al uso de nuevas tecnologías, herramientas o dispositivos. También implican una pérdida de algunos fundamentos básicos que han sido parte integral del proceso de edición.
La idea que propongo consiste en trabajar sobre un modelo de edición estandarizada, multiformato y multisoporte (y que no atenta contra el diseño), conocida como edición ramificada. Para lograr esto es necesario evitar cualquier tipo de enfoque WYSIWYG.
Brian Kernighan dijo una vez que el problema con el WYSIWYG (lo que ves es lo que obtienes) es que en realidad lo que ves es TODO lo que obtienes. No descarto las interfaces gráficas, han demostrado –y continúan– siendo excelentes para muchas tareas, gbTeXpublisher está basado en una interfaz gráfica. Pero también el uso de la consola con un Shell permite una potencia y elasticidad mayor.
El modelo cíclico (la edición que conocemos)
En la figura que se presenta a continuación, se destaca la concentración de la edición cíclica en la capacidad de producir simultáneamente para varios soportes de salida (donde un inicio A se desplaza hacia destinos B, C, etc.). Se busca preservar la noción de que la publicación, en este caso un libro, sigue un único camino. Este enfoque de trabajo se fundamenta en la creencia de que algún software realizará de manera milagrosa la tarea, proporcionando tranquilidad al abordar la conversión a diferentes formatos. Sin embargo, solo al tomar una conciencia real de la pérdida en calidad técnica y editorial, se hace evidente que la edición cíclica no constituye un método óptimo para la producción en formatos y soportes diversos.
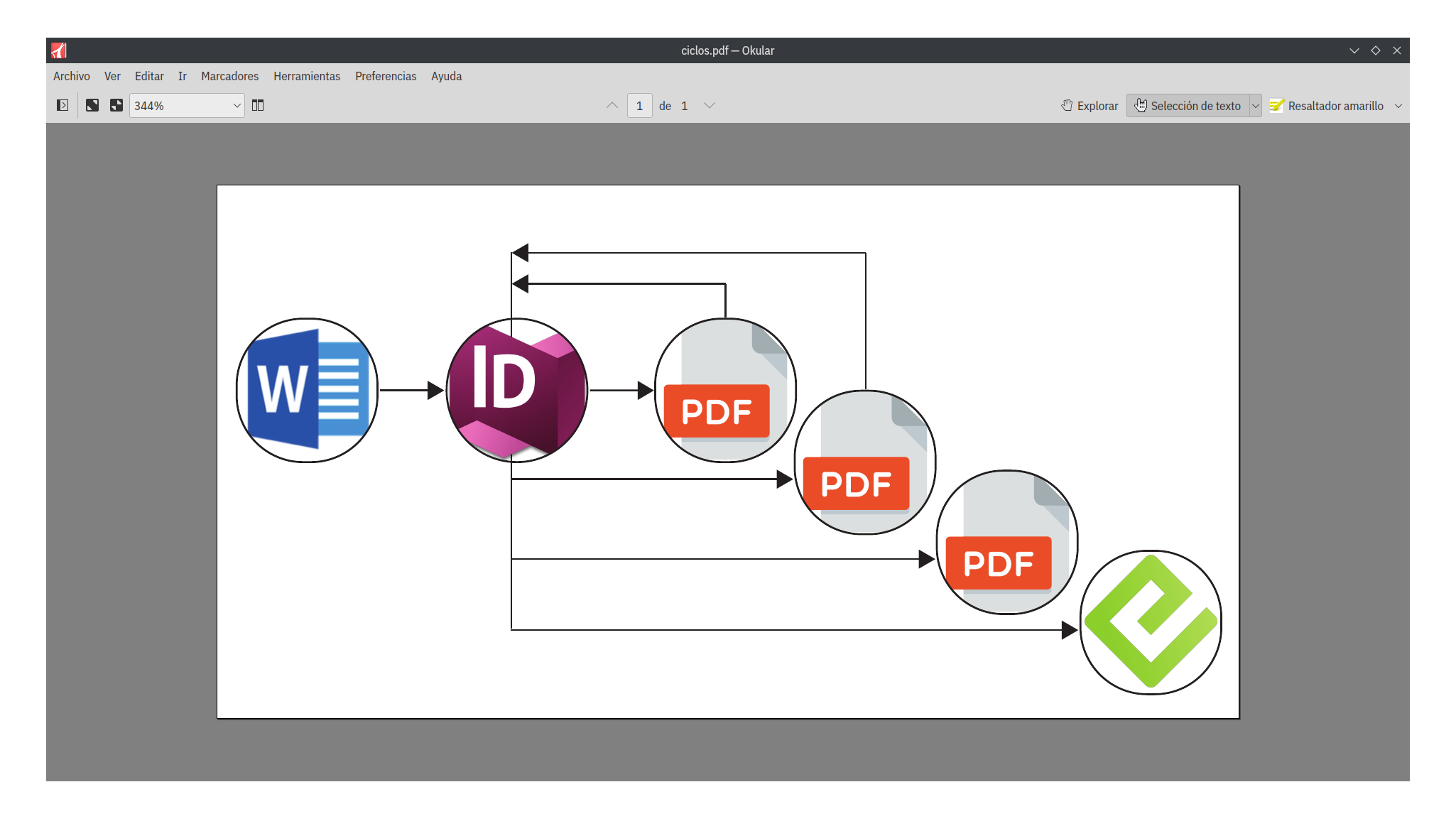
Pero es entendible que esto haya pasado, si observamos como era el modelo de producción editorial antes de la era digital.
La edición ramificada (el futuro por venir)
La edición ramificada es un modelo de producción que implica una apertura en diversos aspectos, para comprender mejor esto se puede recurrir al término single source (fuente única), que refiere a la práctica de mantener un único origen para el contenido y que pueda ser utilizado en diversos procesos y así obtener múltiples destinos de salida. Esto puede aplicarse tanto a la creación como a la gestión y al mantenimiento de los contenidos.
En el tema que nos involucra –la edición de libros y revistas– single source implica tener un único origen para el contenido del libro o revista, que luego se puede adaptar para generar diferentes formatos de salida, como impresión, ePub, HTML o XML.
Desde mi perspectiva, la edición ramificada se presenta como una variante del single source en la que los materiales iniciales dan origen a representaciones gráficas en forma de árbol.
En contraste, el single source convencional tiene como objetivo la creación de gráficos en forma de estrella.
En el contexto de la producción editorial, single source se percibe como una visión más simplificada y repetitiva, ya que en una estructura en estrella, el HTML –por ejemplo– se replica para generar versiones en línea y en formato ePub.
La edición ramificada se caracteriza por tener una perspectiva más compleja y concreta de los desafíos editoriales cotidianos. En este enfoque, se busca mantener el árbol lo más simple posible, adaptándolo a las necesidades y capacidades disponibles.
Una de las ideas que predomina es facilitar la consistencia de los datos y la eficiencia en su manipulación, ya que en lugar de mantener y actualizar varios formatos de salida de un mismo contenido, se trabaja en un único archivo de origen (fuente) desde donde se generan diferentes salidas según sea necesario.
En la edición técnica y en los sistemas de documentación, la edición ramificada también se utiliza para describir el enfoque de mantener una única fuente de información para la creación de manuales, catálogos u otros materiales, lo que facilita la actualización y consistencia en diferentes contextos de uso.
Ahora bien, para empezar a involucrarnos en este modelo debemos hacer el ejercicio de cambiar la perspectiva de producción, realizando un ejercicio de pensamiento lateral.1 La idea es simple: no nos concentremos en los formatos de salida, sino en los caminos que conducen a ellos.
Para facilitar la comprensión de mi explicación, imaginemos que partimos de un archivo fuente. Al seguir el proceso para convertirlo en un PDF, obtenemos un resultado perfecto. Ahora, al utilizar el mismo archivo fuente para generar un ePub, nos encontramos con errores, ya sea en el diseño, la estructura, u otros aspectos. Es crucial corregir estos problemas en el proceso de conversión hacia el ePub, no directamente en el ePub final. Este enfoque garantiza la consistencia en la fuente de los datos.
Para trabajar con este modelo de producción es necesario utilizar algún lenguaje de marcas,2 ¿por qué?, porque hasta ahora la mejor forma conocida de producir es separando la estructura del contenido de su modelo de representación visual y esto se consigue aplicando marcas (etiquetando) a las partes del documento, ya que se pueden incorporar todas las que sean necesarias acerca de la estructura y el diseño para la representación del texto en la salida buscada.
La figura a continuación nos muestra un modelo (de todos los posibles) de edición ramificada, donde no existe una secuencia de A con B, sino un inicio de (A) con posibles caminos continuadores (B, C, D, etc.), algunos pueden frenar su andar al llegar a su destino final, otros pueden bifurcarse y convertirse en el inicio de un nuevo camino.
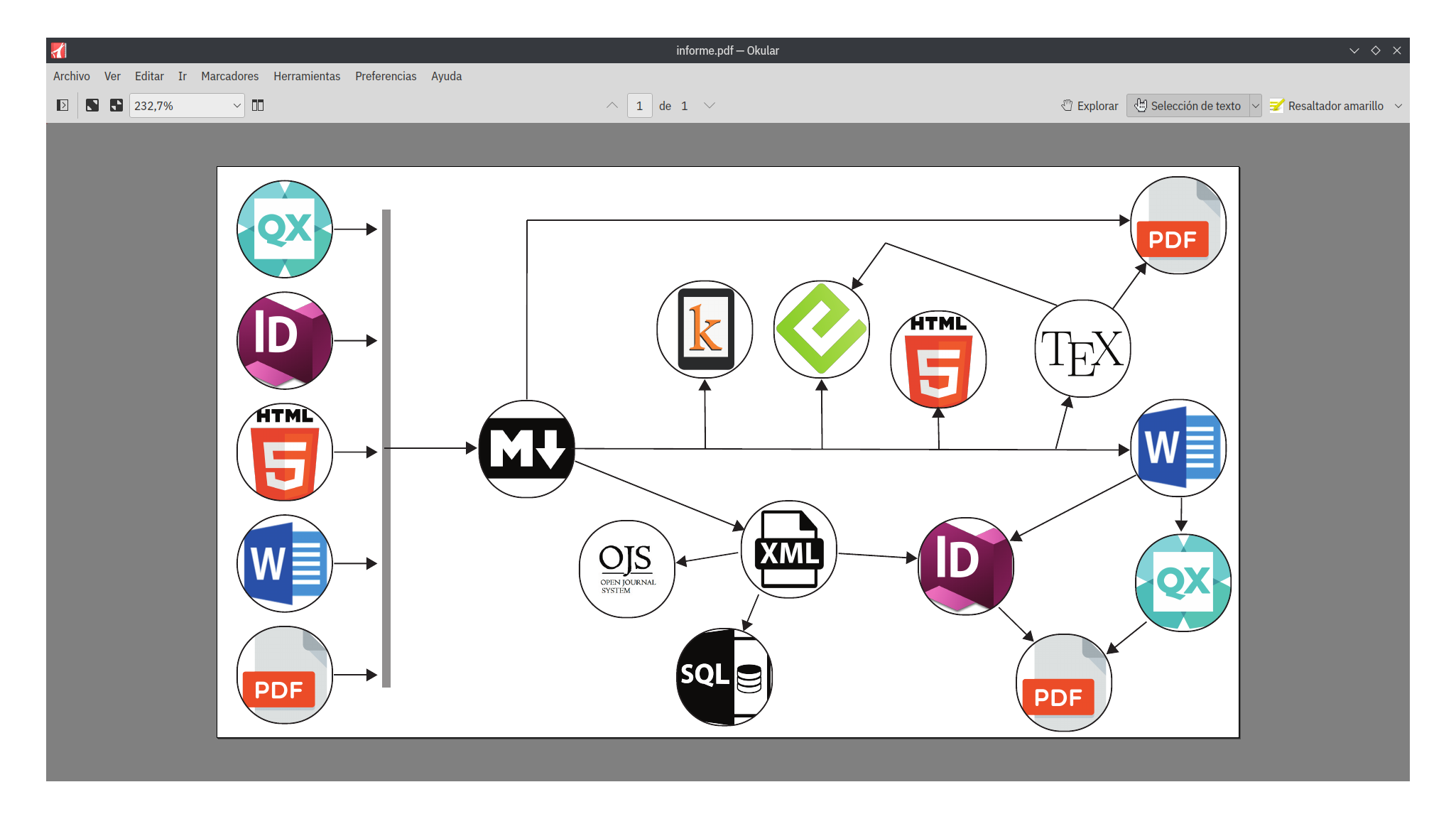
El ejemplo de la figura es uno de los tantos posibles, que tiene su base en el lenguaje de marcas Markdown, pero también existen otros lenguajes como asciidoc, Org Mode y por supuesto LaTeX.
gbTeXpublisher sigue el modelo representado en la figura que sigue.
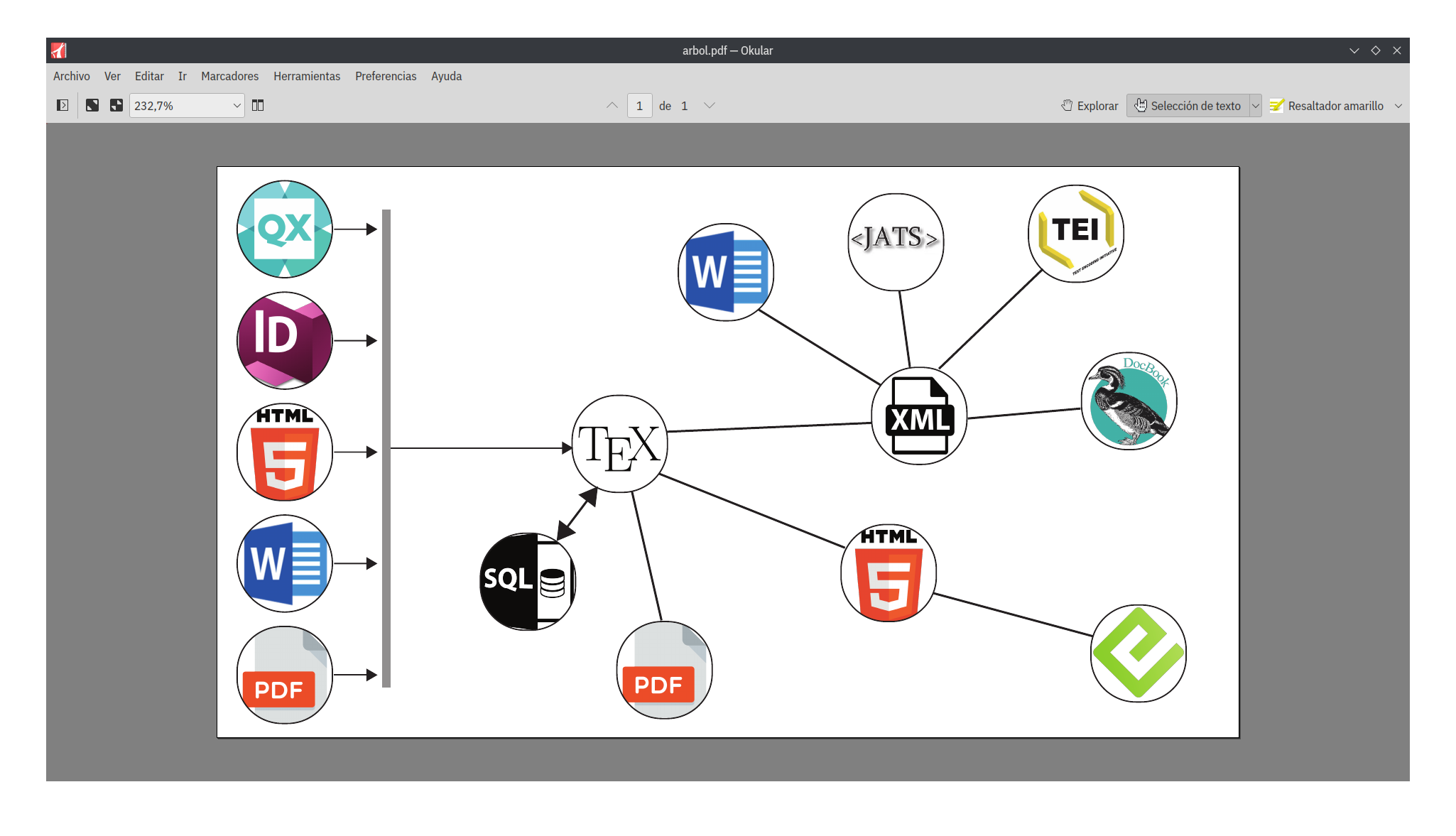
La principal consigna que persigue este modelo es ir de lo simple a lo complejo. Cada formato de salida tiene sus propias necesidades particulares. El PDF para pantalla no es exactamente igual al de imprenta (los hipervínculos hacen una gran diferencia); en el ePub puede hacerse necesario configurar de otra manera las figuras o cuadros; en HTML se puede sacar provecho de la visualización interactiva y así un largo etcétera y como punto de inflexión vamos a encontrar una cuestión clave en Ciencia Abierta, los metadatos.3 Por consiguiente, lo que se hace imperioso es evitar la herencia de características, que es el principal problema que conlleva la metodología cíclica, a diferencia de esta, la edición ramificada se inicia con un documento simple de texto plano que contiene solo las marcas de los elementos estructurales (que a su vez pueden contener el diseño), para luego con ajustes –manuales o automatizados– obtener cada salida que evite la herencia de características indeseadas.
Este es un ejemplo conceptual de la lógica a seguir, supongamos que tengo una marca de cita:4
- Si la salida es a PDF se aplica «Q» diseño y valor de estructura.
- Si la salida es a ePub se aplica «X» diseño y valor de estructura.
- Si la salida es a XML se aplica «Y» diseño y valor de estructura.
- Si la salida es a HTML se aplica «Z» diseño y valor de estructura.
Cada salida tiene su propia lógica para su destino, subordinada a un solo patrón de diseño estructural.
Furtado5 plantea que en una primera aproximación, las ediciones se diferencian entre ellas por la predominancia que tienen las actividades primarias en la transformación físico-técnica del contenido, esto implica que, desde el punto de vista de la edición, el diseño estructural goza de muchísimo valor.
Algunos desarrollos que investigué
El proyecto está archivado, su desarrollador (Ramiro, alias perro tuerto) en una comunicación telefónica que tuvimos hace unos años, me dijo que el proyecto tiene errores de diseño que no le permiten evolucionar, pero tal como está, si lo que se pretende es solo obtener una salida a ePub desde markdown, el software no tiene fallas, y doy fe, lo utilice para hacer ejercicios y funciona, pero tiene tanta solidez como limitaciones. Me a notificado Ramiro que en los últimos tiempos ha tenido una actualización que permite obtener PDF y HTML al vuelo.
Es básicamente un sistema de publicación, posee salida a HTML, ePub y PDF –y funciona muy bien– lo utilicé durante un tiempo, para textos simples se puede escribir directamente en markdown (el sistema hace la conversión a LaTeX) o en su defecto en LaTeX. Está escrito en lenguaje Ruby y algunas partes del sistema son muy cerradas (en su diseño) lo cual hace muy cuesta arriba pretender hacer modificaciones al código. Pero si la matriz de producción editorial está definida y es simple, es una buena opción para trabajar.
En el sitio de Transpect se explica muy simple:
Transspect fue diseñado para proporcionar módulos genéricos y estables para tareas comunes de conversión y verificación. Para abordar datos complejos y diversos, transspect ofrece una configuración en cascada para anular reglas específicas de transformación y verificación. Cada componente dentro del marco es de código abierto y utiliza tecnologías estándar como XSLT 2.0 y XProc.
Este proyecto es, lo más de lo más (utiliza TeX y XML como base), pero cuando intenté ponerlo en marcha me di cuenta de que solo es viable en grupos editoriales con altos volúmenes de producción, ya que su implementación no es simple, sino más bien lo contrario. Solo alcanza con ver los clientes de le-tex, que son los desarrolladores, para entender esto.
Un ecosistema en si mismo…
Luego de varios intentos me dí por vencido, esta imagen de El Eternauta, se me vino a la mente cuando escribía este artículo.
{kind=link}
Existen más proyectos girando en torno a la edición ramificada y no tuve tiempo de estudiarlos (también debe haber otros que no conozco), de los más interesantes que me quedaron como deuda está el de la editorial O’Reilly (HTMLBook), utiliza asciidoc como lenguaje base para las marcas.
Para los diseños utilizados en revistas complejos de codificar, también es posible aplicar la metodología sugerida por le-tex, que es salir a un archivo XML y trabajar el diseño desde InDesign o QXpress, en este modelo se suma un posible conflicto de control, pero es el precio a pagar para diseños específicos.
Resulta intrigante notar que muchos proyectos de edición ramificada optan por emplear LaTeX como ruta secundaria para la generación de archivos PDF. Esta observación me llevó a reflexionar sobre la primacía en los proyectos, es decir, si la generación de archivos HTML o ePub tiene mayor prioridad que la producción de archivos PDF. En este contexto, surge la consideración de que elegir producir directamente en Asciidoc, por ejemplo, podría ser una opción de trabajo más eficiente cuando la salida a PDF no es la principal prioridad.
Todos los caminos conducen a LaTeX
Conocí LaTeX en el año 1993, pude ver el resultado de sus compilaciones en una PC con MS-DOS, recuerdo que me sorprendió mucho, pero no fue hasta 10 años después que lo empecé a usar de manera cotidiana e intensiva, cuando abandone la preprensa y la imprenta para dedicarme de lleno a la edición científica.
Esto no impidió que en los últimos años haya trabajado con Markdown y AsciiDoc (con el intérprete asciidoctor), y aún hoy los sigo usando (los artículos de este blog los escribo en markdown), también hice algunas pruebas con PlasTeX.
Intentar hacer una muestra de las capacidades de LaTeX en la producción editorial sería interminable, ya que no hay límites como los que se pueden encontrar en una aplicación de DTP (donde las capacidades del programa determinan que es posible hacer y que no) en LaTeX no hay límites, el límite está en el conocimiento que se tenga de él (por eso es un lenguaje).
Botones para muestra
Para poder graficar mejor lo dicho en el párrafo anterior, dejo ejemplos de características obtenidas en mi trabajo diario con LaTeX, que son imposibles de obtener con programas para DTP del mercado y que muestran mejor a que me refiero cuando utilizo la expresión alto estándar de calidad tipográfica.
Homeoarchy
Control de inconsistencia de principio y fin de linea.6 En este artículo que escribí hace unos años doy mayores detalles sobre este tema.

Formateo automático ortotipográfico
Se puede observar que la tabla de la base de datos, no contiene bastardillas, ni puntos, ni versalitas, etc.
@Book{Mazlish1995,
hyphenation = {spanish},
author = {Mazlish, Bruce},
date = {1995},
keywords = {listar},
location = {Madrid},
publisher = {Alianza Editorial},
title = {La cuarta discontinuidad},
}
Y esta es la salida que se obtiene en el PDF para el modelo autor-año con el estándar del paquete biblatex-philosophy.

Posición de los objetos en la página
Se tiene control absoluto sobre cualquier posición x-y de la página para posicionar objetos, incluso otra página (que también se interpreta como un objeto).

Estos ejemplos son solo la punta del iceberg, puede sonar exagerado, pero se entiende mejor cuando se asimila a LaTeX como lo que es, un lenguaje para la composición tipográfica, y no como un programa de armado.
Pequeña radiografía de LaTeX
LaTeX es un lenguaje de composición tipográfica, orientado a la creación de documentos escritos con un alto estándar de calidad tipográfica. Por sus características y posibilidades, es usado de manera intensiva en la generación de textos científicos. Fue escrito por Leslie Lamport en 1984, con la intención de facilitar el uso del lenguaje de composición tipográfica TeX, creado por Donald Knuth. A resumidas cuentas, LaTeX no es mas que un conjunto de macros de TeX, y se encuentra bajo licencia LPPL.
El patrón de escritura que maneja LaTeX (no es el único lenguaje que trabaja de esta manera) es separar la estructura del contenido de la representación visual de la salida, aún teniendo todo dentro de un mismo archivo de texto plano.
Los archivos de LaTeX presentan una primera división de dos partes:
- Preámbulo (documentclass)
- Contenido (document)
Podemos decir que un archivo de LaTeX es la suma del contenido mismo en texto plano, más las instrucciones (etiquetas), también en texto plano.
\documentclass{book}% acá comienza el preámbulo
% carga de paquetes y funciones
\begin{document}% acá comienza en documento
% contenido y funciones
\end{document}% fin del documento
A su vez, la segunda parte (document), en su estructura también tiene divisiones internas.
- Frontmatter
- Mainmatter
- Appendix
- Backmatter
La siguiente es una descripción básica, la división estructural se puede incrementar aún más.
...
\begin{document}% acá comienza en documento
\frontmatter
% en el mundo editorial este espacio también es conocido como «primeras»
% y se autonumera con romanos en mayúscula para español
% y en minúscula para inglés (por ejemplo).
\mainmatter
% cuerpo principal del texto dividido en capítulos
\appendix
% apéndices
\backmatter
% listado de índices
\end{document}
Este artículo no es un curso de LaTeX, en la red hay a montones,7 pero con esta explicación particular se va a entender como trabaja gbTeXpublisher.
¿Entonces?
El preámbulo es la parte en donde se declaran las diferentes macros que darán instrucciones precisas al compilador para la salida que se desea obtener, ahora bien, los paquetes y macros están sujetos a 2 características principales.
- trabajan sobre la salida (por ejemplo geometry que permite manipular el diseño y la estructura de la página).
- intervienen en el contenido (por ejemplo csquotes que automatiza el manejo de las comillas).
El punto 1 es crucial entenderlo, ya que es donde todos los sistemas fallan, las necesidades que tiene una salida (no importa cual) no son necesariamente las mismas que tiene otro tipo de salida (no importa cual). Aquí es donde mejor se comprende por qué es necesario evitar la herencia de características.
A su vez, los paquetes que trabajan sobre la salida, pueden:
- ser incompatibles entre sí;
- tener dependencia de otros paquetes.
Frente a la cantidad abrumadora de paquetes disponibles en el CTAN,8 sin contar que está la posibilidad de escribir macros propias o incluso de interactuar con otros lenguajes (por ejemplo Lua)9 o metalenguajes (por ejemplo Tikz), lo primero a resolver era cuál camino seguir.
- un preámbulo único, regido exclusivamente por condicionales10 que controlen todo el flujo, con el nivel de riesgo que esto conlleva, ya que cualquier cambio –por mas simple que fuera– puede alterar toda la cadena del flujo a seguir.
- varios preámbulos, ajustados a cada tipo de salida.
El camino que tome es el 2. No es el camino esperado por muchos programadores con los que hablé, pero no soy programador. La figura a continuación ilustra la idea.
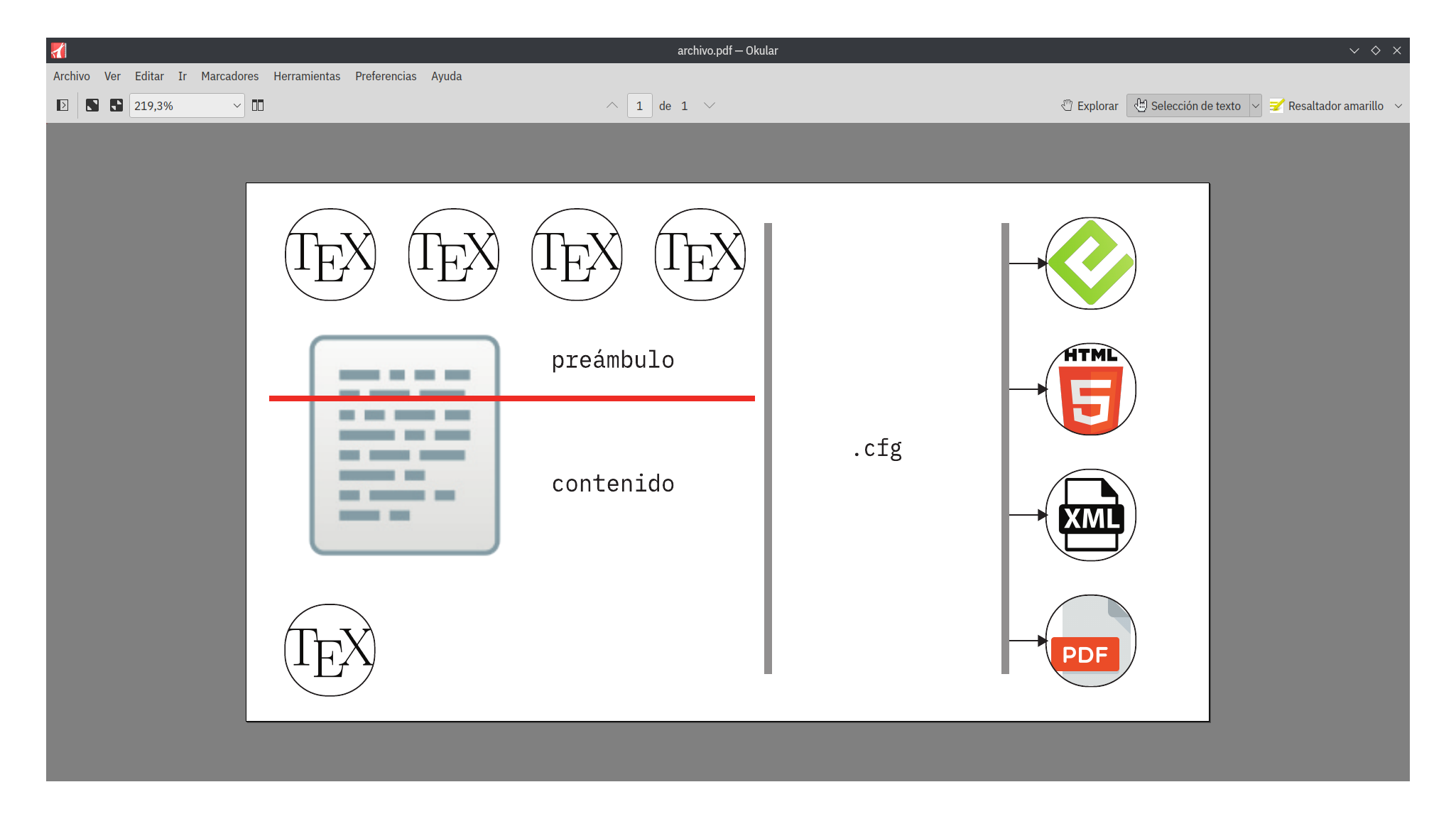
Entonces, como sigue; gbTeXpublisher lo que hace básicamente es concatenar el preámbulo más la configuración más el contenido en un solo archivo y pasárselo al compilador para que haga su trabajo.
Lo más importante que rescato de este modelo, es que si me encuentro con la necesidad de cambiar el diseño (visual o estructural) de la salida, poder modificar los diferentes archivos involucrados en cada compilación es fácil y con poco (casi nulo) margen de error, no confundir esto con manejar el lenguaje LaTeX, esto último es excluyente.
La figura a continuación muestra un resumen de cómo es el flujo de trabajo, es importante resaltar la posibilidad que existe de recuperar cualquier trabajo antiguo, indistintamente del formato que tenga.
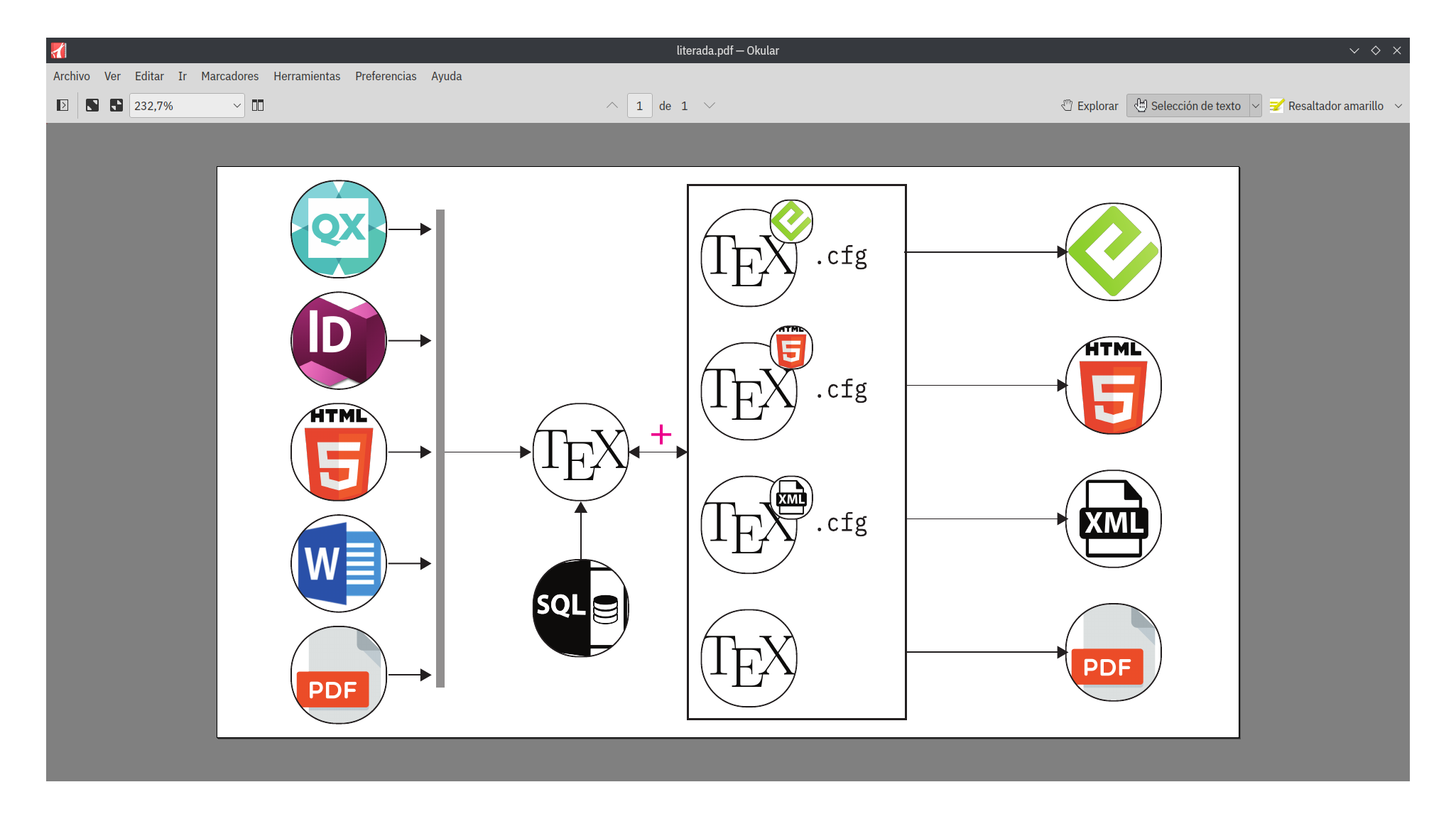
El motor SQL lleva la tarea de centralizar toda aquella información que pudiera ser reutilizada, evitando la redundancia de datos. La inyección de los datos se hace de manera automática y el ABM (alta, baja y modificación) de los datos se trabajan desde los diferentes formularios que posee gbTeXpublisher.
Descarga e instalación de gbTeXpublisher
Doy por descartado que LaTeX ya está instalado, sugiero tener instalada la versión full (aproximadamente 4 gigas). Personalmente, para editar los textos utilizo TeXstudio desde hace ya varios años, pero sirve cualquiera de los editores que se encuentran en Internet.
También es necesario tener una cuenta en gitlab, para hacer uso del respaldo remoto, los 10 gigas de la versión gratuita son más que suficientes.
Si bien en Gambas (el lenguaje que utilicé para escribir gbTeXpublisher) es posible hacer el empaquetado para las principales distribuciones de GNU Linux, para evitar posibles conflictos, lo que está disponible es un empaquetado autotools.
Este es el link de descarga para la última versión disponible (gbTeXpublisher).
En el siguiente video muestro el proceso de instalación.
Para los que quieran hacer una bifurcación del proyecto o descargarlo y compilar desde las fuentes, esta es la ruta de gbTeXpublisher en GitLab.
Los usuarios de windows pueden utilizar el software a través de WSL, considero que es preferible tener un doble arranque (windows/linux), pero cada uno analiza en que situación se siente más cómodo.
A los usuarios de MacOS, no sé que decirles, no tengo acceso a esos equipos desde hace muchos años. Si alguien quiere hacer pruebas quedo a disposición para ayudarlo en lo que pueda.
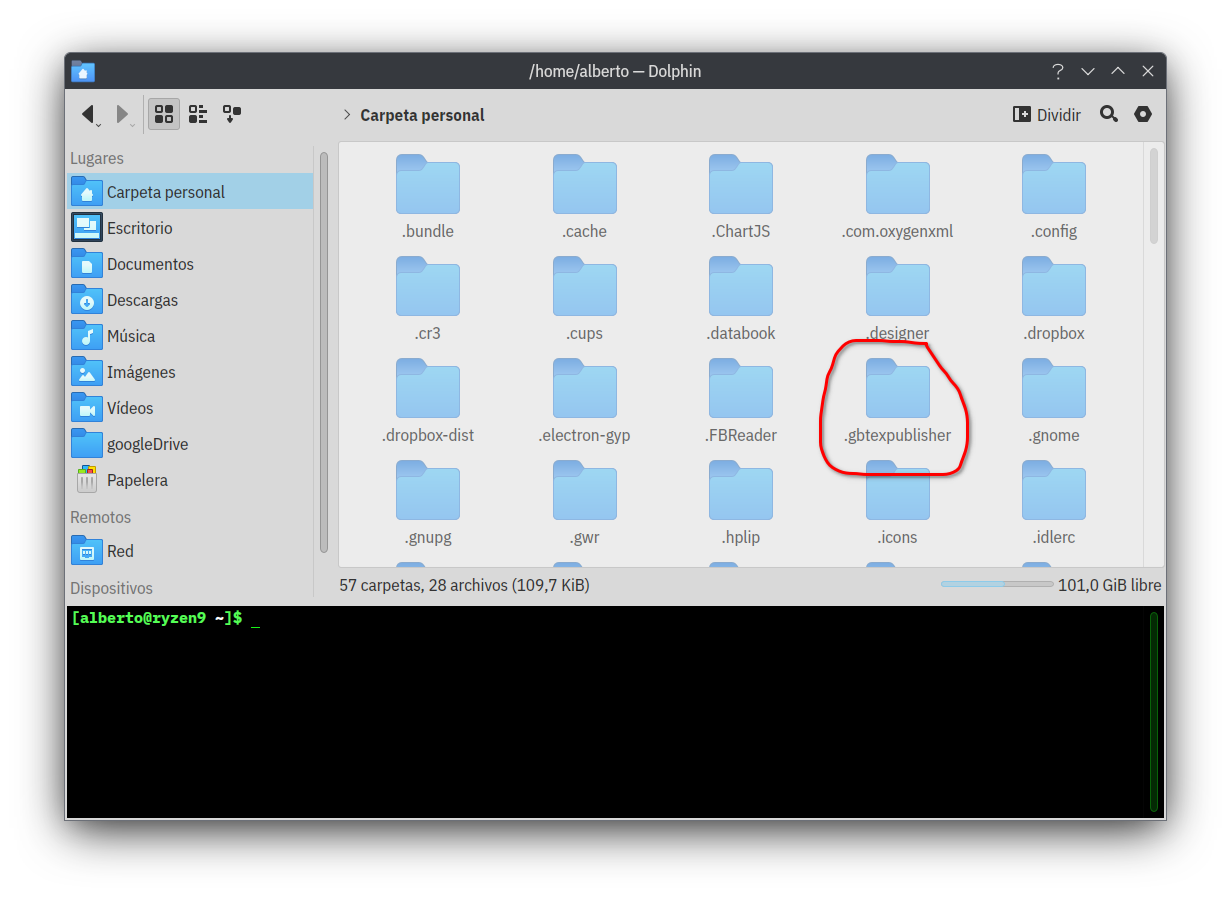
Con el fin de proporcionar una visión integral de las funciones de la instalación, es importante destacar que después de completar la instalación de gbTeXpublisher, se generará una carpeta oculta en el directorio home.user (denominado también como directorio personal). Esta carpeta albergará la base de datos, y durante el proceso de instalación, se copiará una base de datos preexistente con un número específico de entradas. Estas entradas son fundamentales para el estudio de notas, acrónimos y referencias bibliográficas. En la figura siguiente, este aspecto se destaca visualmente mediante una línea roja para mayor claridad.
Comenzando con gbTeXpublisher
Cuando se está editando un solo libro, se pueden tener ciertas libertades, pero cuando se tienen 7 o 9 libros de manera constante en el flujo de producción, la cosa cambia. El orden y el principio de DRY se vuelve más que importante si queremos tener una sana optimización de los recursos. En gbTeXpublisher se van a encontrar funciones predefinidas (y rígidas) que aseguran comportamientos estables y predecibles.
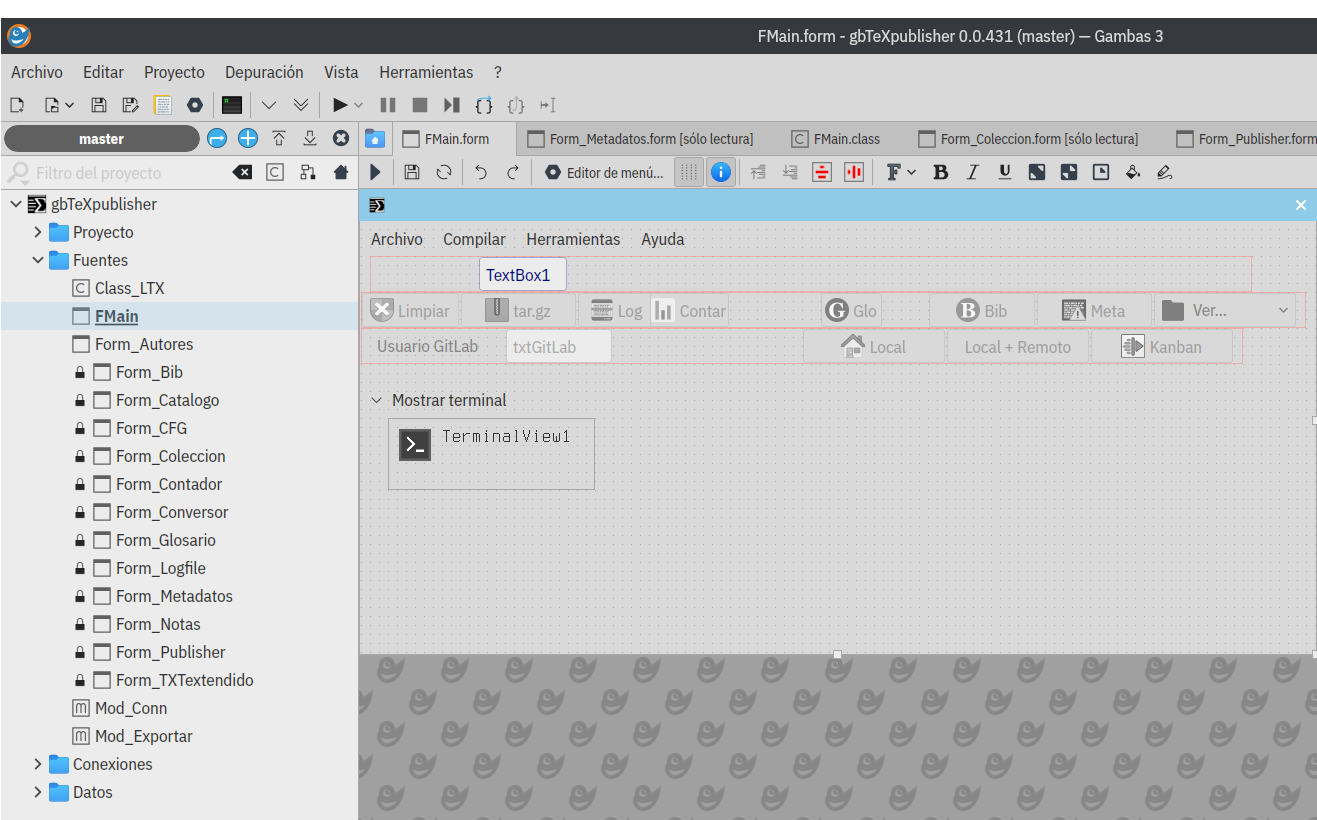
El programa no trabaja sobre el archivo de LaTeX, sino que lo hace con una copia. Esto da plena y absoluta libertad de trabajar el texto con el editor que mejor le plazca al usuario. De ahí que su interfaz de inicio pueda sorprender –ya que no dice nada– esto también se observa al notar que algunos menúes están deshabilitados y se activan una vez que se haya elegido un archivo con el cual trabajar. La imagen a continuación lo ilustra.
Una vez que hayamos seleccionado un archivo para trabajar, la pantalla puede parecerse a esta.
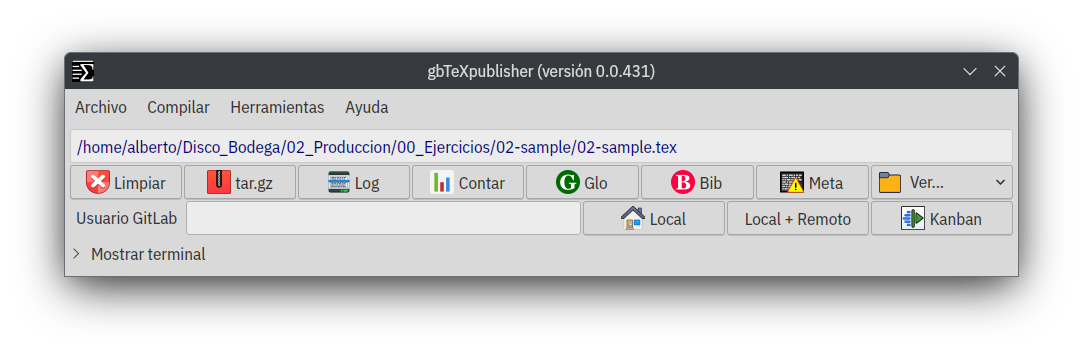
Volviendo al inicio, en un párrafo anterior dije que algunos menúes están deshabilitados hasta que se elija un archivo .tex para trabajar, pero otros sí están habilitados.
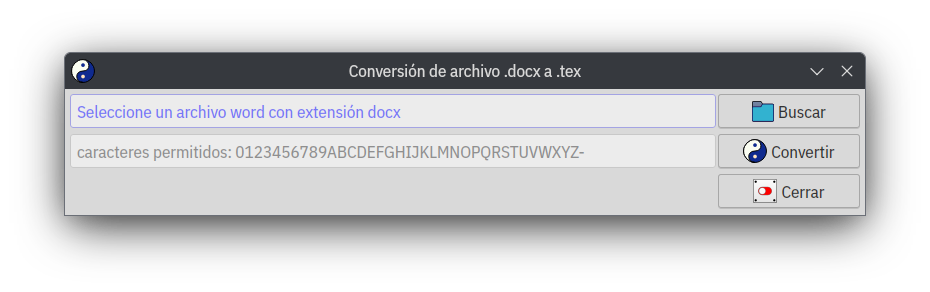
El primero que encontramos es el formulario para la conversión de archivos word (.docx) a formato .tex, el proceso se realiza utilizando pandoc, junto con la conversión se realizan otras dos tareas más:
- se crean dos carpetas –originales y media– dentro del directorio de trabajo;
- se mueve el archivo word a la carpeta originales.
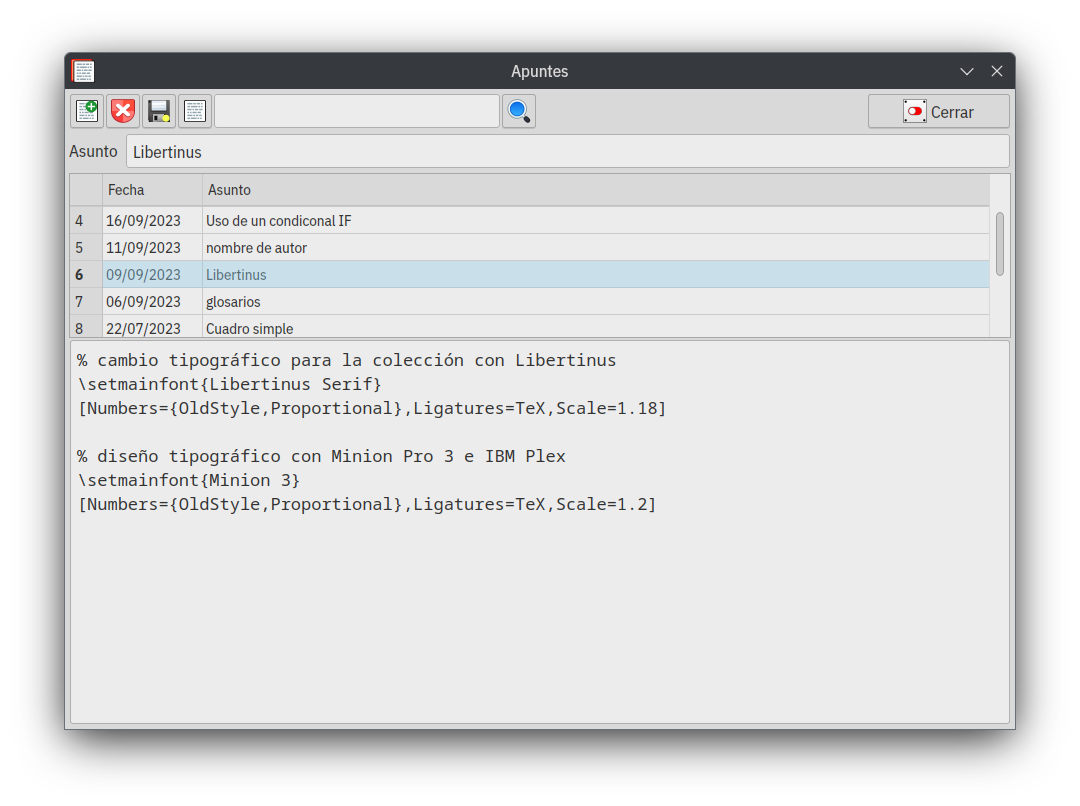
El segundo es el formulario de apuntes, su idea y desarrollo surgieron de manera natural. Antes de gbTeXpublisher, a medida que iba trabajando tomaba apuntes sobre el proceso, ya sea consultas que debía hacer (al autor, al corrector o a mi cliente), buscar en otros archivos ese pedazo de código que alguna vez utilicé o simplemente apuntes de ayuda memoria temporal, todo eso es lo que se vuelca en este formulario, la información queda almacenada en la base de datos para ser recuperada cada vez que sea necesario.
Las notas pueden ser exportadas a formato .docx para ser enviadas por correo o impresas.
Configurando las salidas
gbTeXpublisher utiliza como motor de conversión subyacente make4ht que es un sistema de compilación simple para tex4ht.
Importante: gbTeXpublisher, técnicamente está maduro, lo utilizo en mi producción diaria. Sigo con correcciones vinculadas a tips de producción de mi día a día. Entonces, ¿por qué hago mención de que es un beta? Porque seguramente, si empiezo a recibir consultas surjan otras cuestiones a revisar.
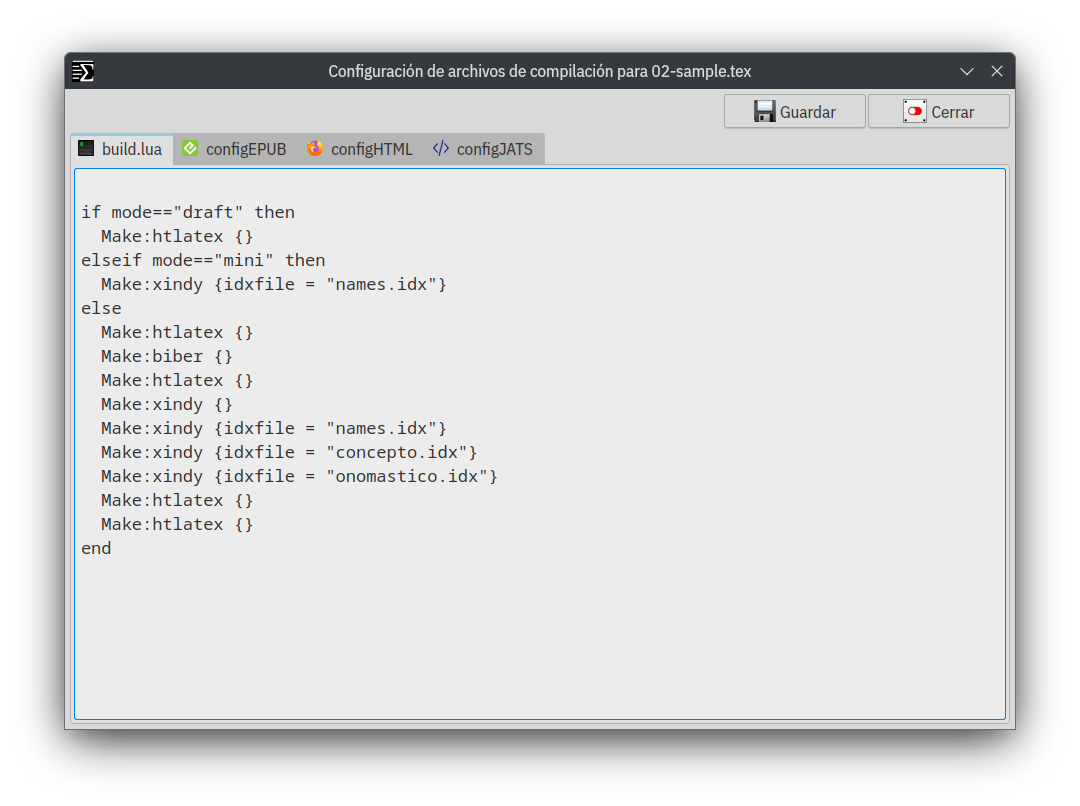
Los archivos .cfg que el programa instala tienen una configuración base general, y mi intención es poder optimizarlos. Reitero: en estos archivos es donde se hacen cambios cuando se pretende alterar la salida más allá del diseño visual.
El archivo build.lua trae por default una configuración base pensada para no dejar ninguna posibilidad fuera de su alcance, si alguna de sus instrucciones no fuesen necesarias (por las características del archivo con el que se está trabajando), no es problemático dejarlas, ya que el error que nos dará el compilador es del tipo suave, y por supuesto, si el archivo con el que trabajamos lo requiere, este archivo de configuración puede modificarse sin problemas.
La indexación para las siglas y el glosario está codificado en el preámbulo que viene por default.
No hay un archivo de configuración para PDF, esta es la salida natural, por consiguiente, todas sus características están dadas en el propio código del archivo.
Para los archivos de configuración para ePub, HTML y XML, la suerte es la misma, quiero decir, contemplan una salida general en términos de posibilidades, que pueden ser modificados según cada necesidad.
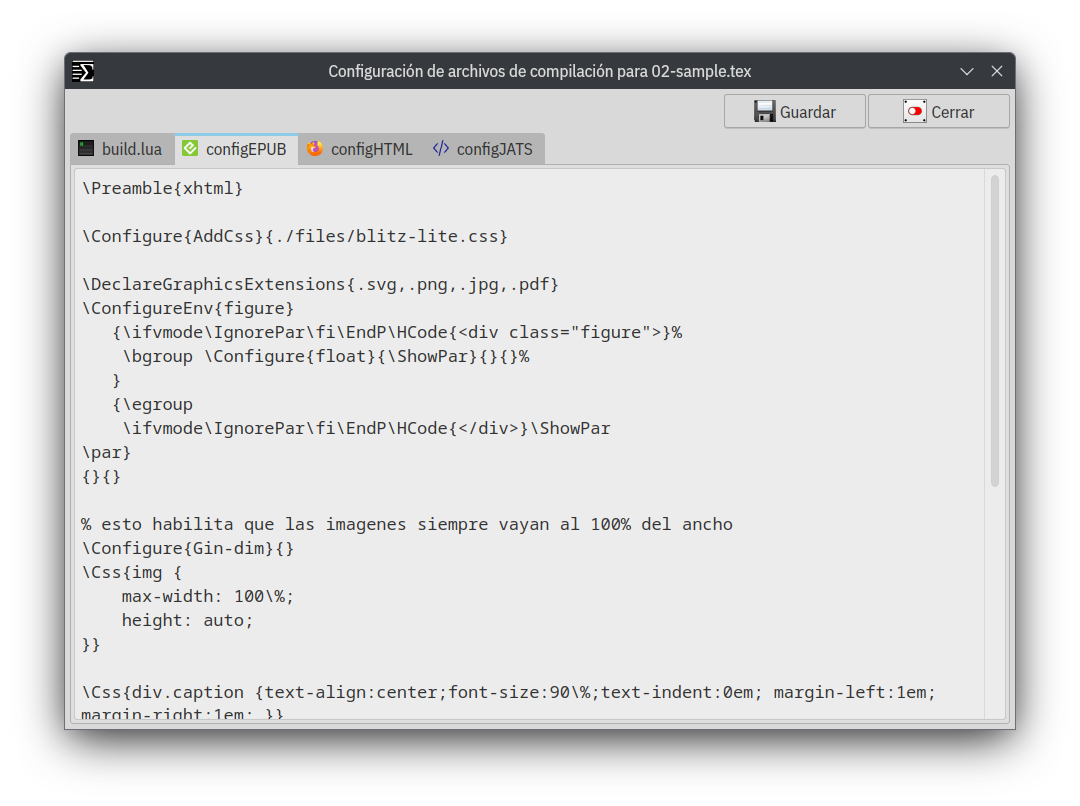
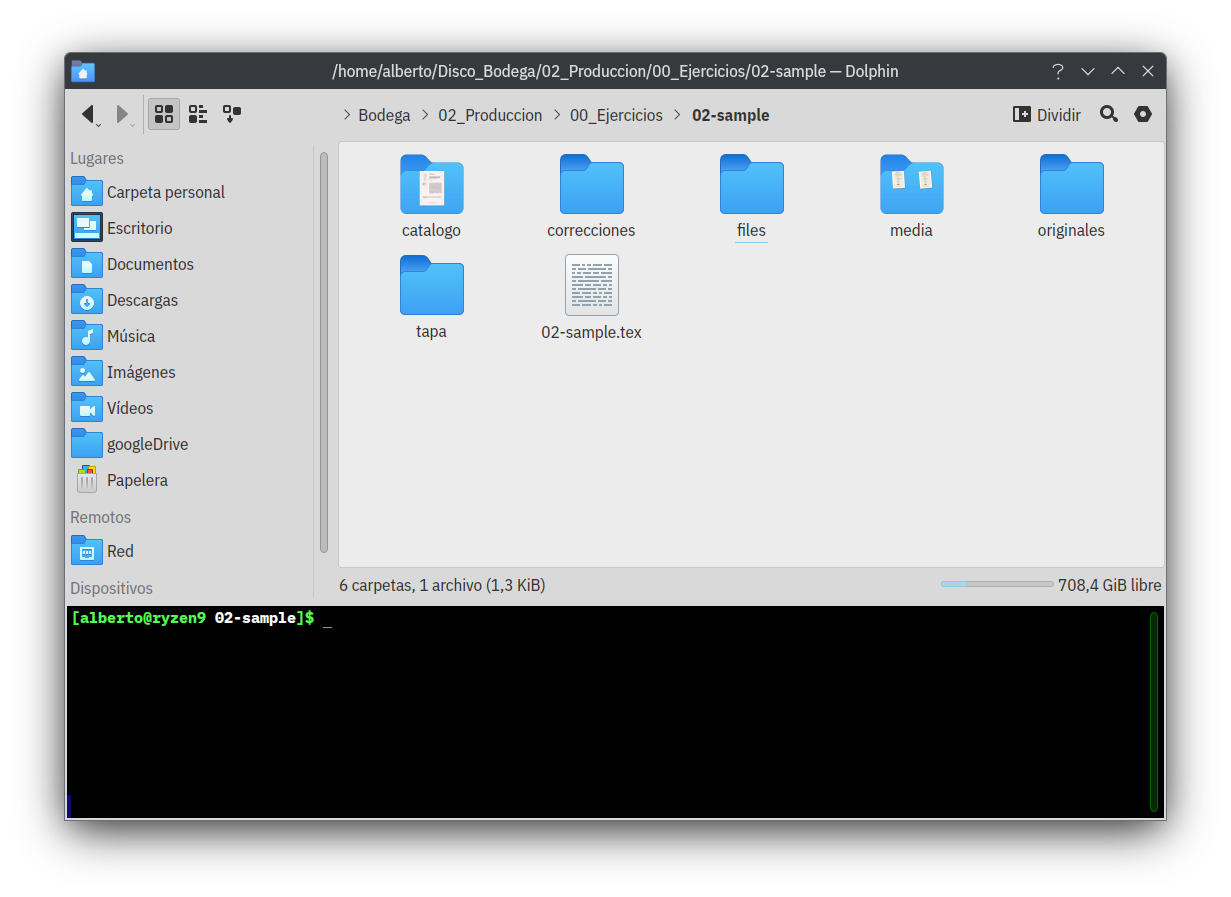
Ahora bien, comenzamos con el trabajo
Luego de seleccionar un archivo, si miramos la carpeta contenedora del proyecto, veremos que se han creado nuevos directorios:
- catalogo
- correcciones
- files
- media
- originales
- tapa
Si los directorios originales y media, ya existian porque se hizo la conversión de .docx a .tex utilizando gbTeXpublisher, estos no se sobreescriben y se mantiene sin modificaciones su contenido.
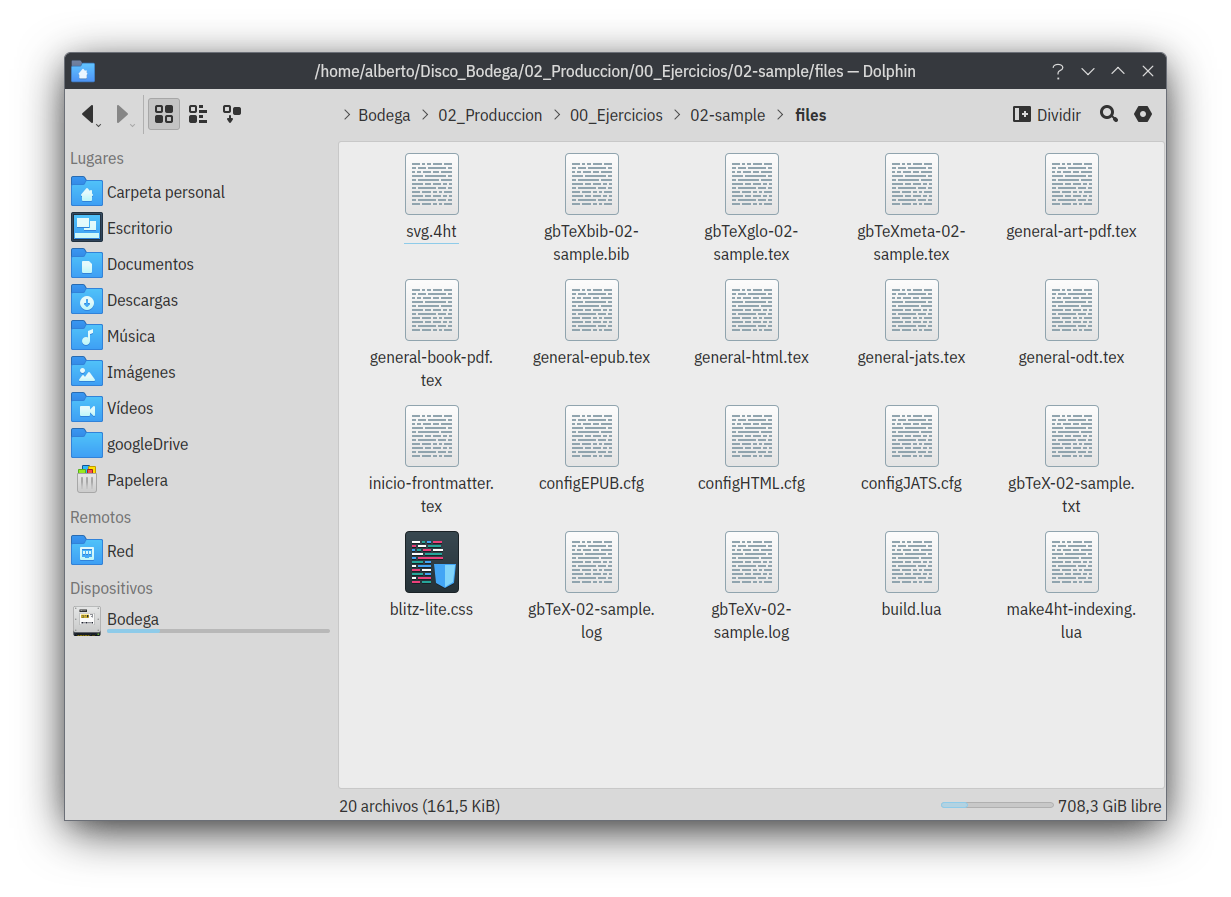
Dentro del directorio files se agregaran los archivos auxiliares y complementarios para la compilación, estos son los diferentes preámbulos y archivos de configuración, si cualquiera de estos archivos fuera modificado (no importa si desde gbTeXpublisher o desde un editor externo), no será reemplazado al volver (en un momento diferente) a cargar la aplicación, solo será agregado nuevamente aquél archivo que por error hubiera sido eliminado.
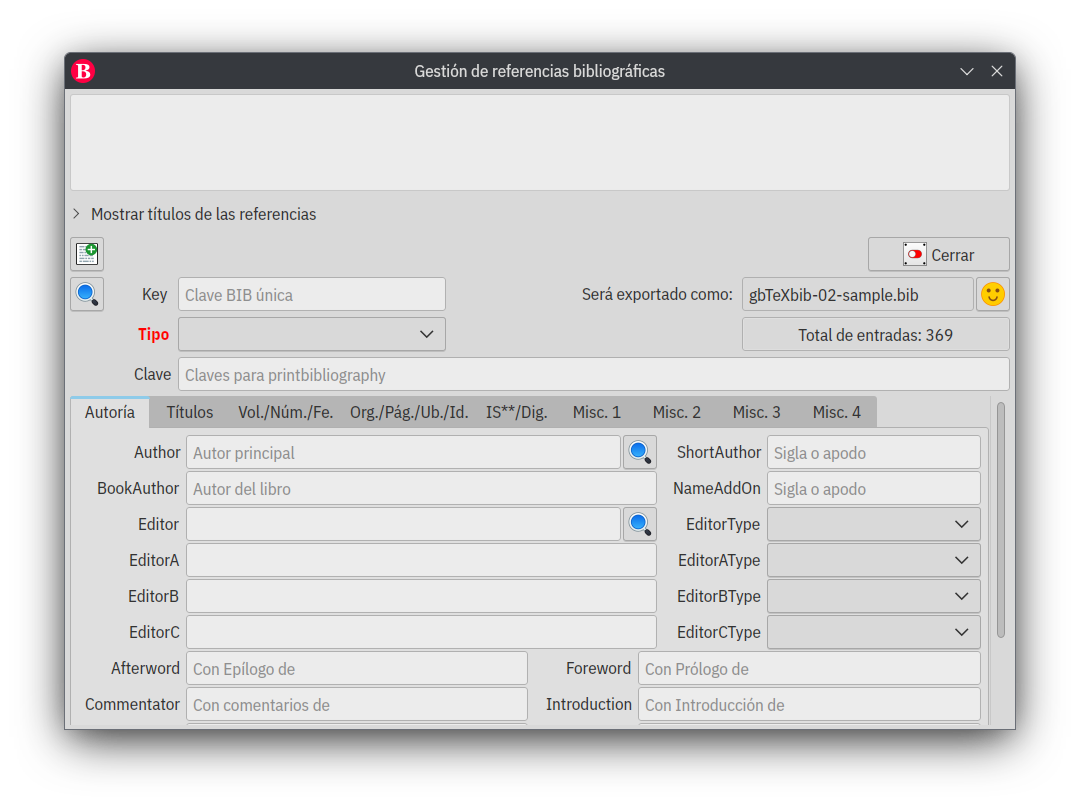
Referencias bibliográficas
A continuación vemos el formulario para manejar las referencias bibliográficas, el programa trabaja con un motor de base de datos SQLite, que para trabajar en modo local, es lo mejor que conozco, pero si el trabajo se quisiera realizar en modo colaborativo (en red, abierta o cerrada), se debería migrar a otro motor.
Todas las entradas están basadas en BibLaTeX que es una reimplementación completa de las funciones bibliográficas proporcionadas por LaTeX. El formato está completamente controlado por macros de LaTeX. BibLaTeX utiliza su propio analizador de datos llamado biber (escrito en Perl) para procesar los datos bibliográficos.
Por default gbTeXpublisher para la clase book entrega un archivo configurado para la salida a PDF con el estándar autor-año (diseño moderno) desarrollado por Ivan Valbusa en la Universidad de Verona (biblatex-philosophy), para la salida a ePub, XHTML, HTML5 y XML se utiliza el estándar biblatex-iso690 y para la salida a PDF en la clase article se utiliza el estándar de APA y, por supuesto, todas estas salidas se pueden modificar e incluso cambiar.
Para explicar el uso de las referencias junto a la lógica que muestra cómo se separa la estructura del contenido de la representación visual de la salida, la mejor forma es a través de un video.
En este otro video se puede observar un uso exhaustivo del módulo que maneja las referencias bibliográficas.
Siglas y glosarios
Las siglas y glosarios se pueden dar de alta desde este formulario, lo que implica que quedan registrados en la base de datos, esto permite la reutilización de los valores, también es posible agregar entradas directamente en el archivo .tex.
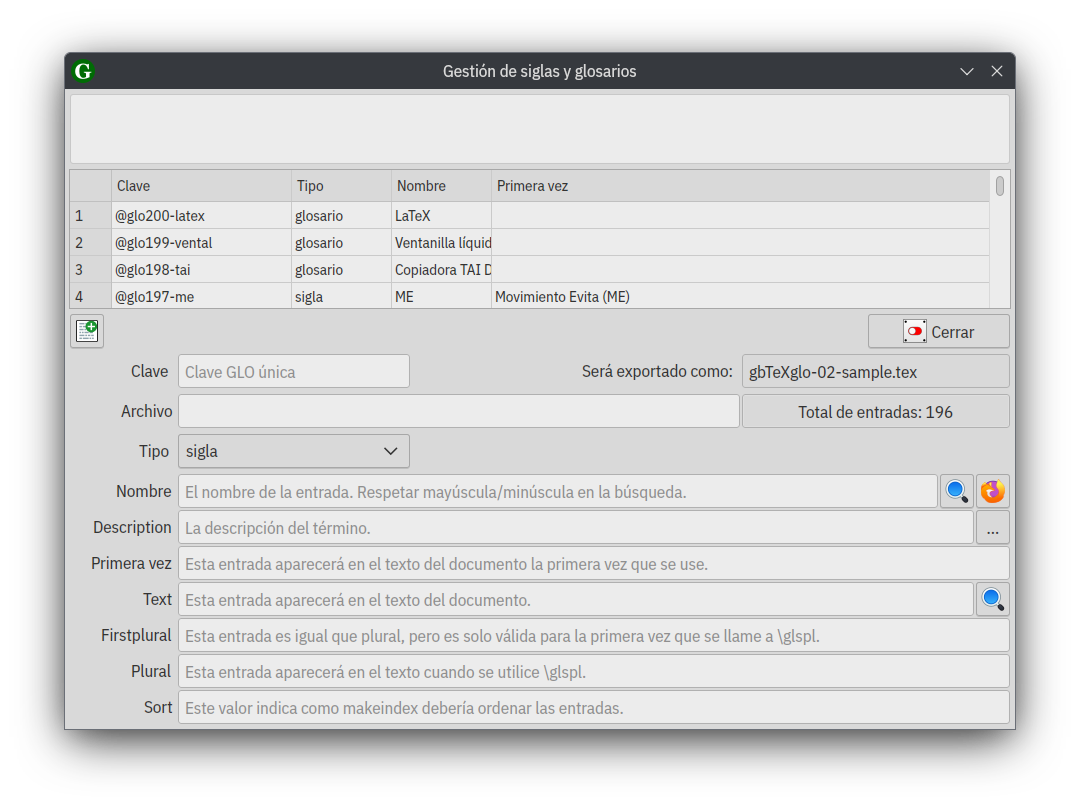
Al igual que con las referencias bibliográficas, en el siguiente video doy una vista general del modelo de trabajo.
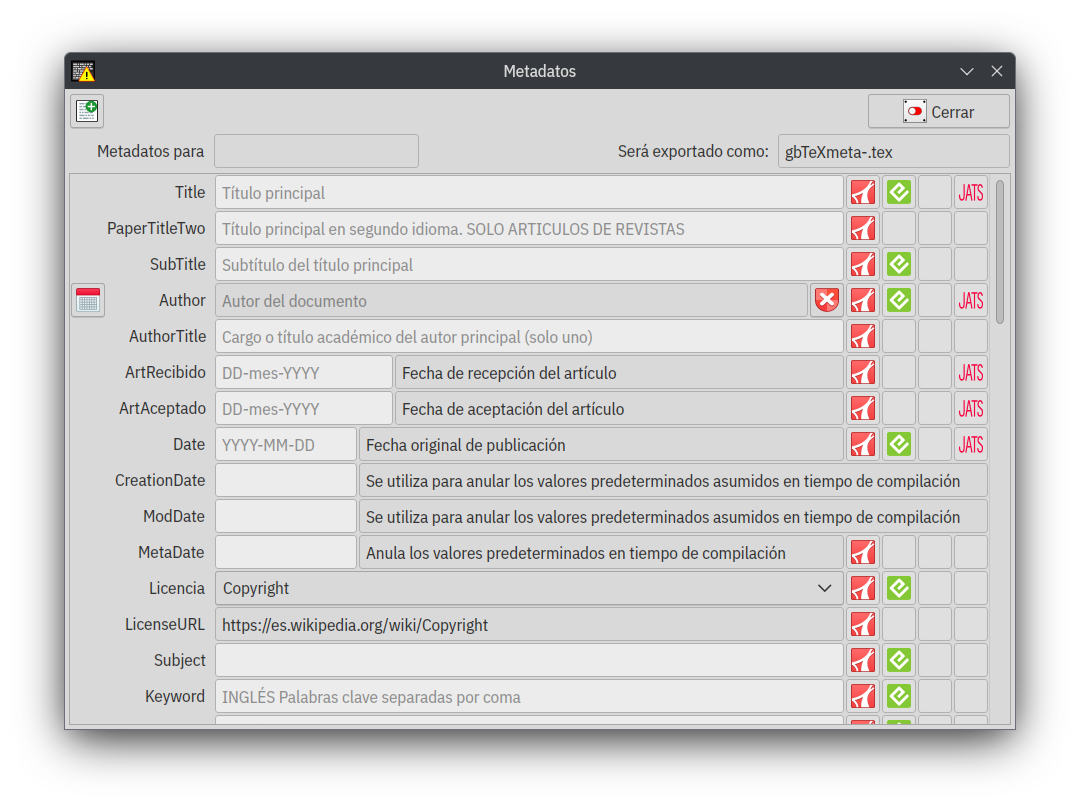
Trabajando con los metadatos
La información contenida en el formulario de metadatos es utilizada en las diferentes salidas, a la derecha los íconos muestran en que salida impacta esa información.
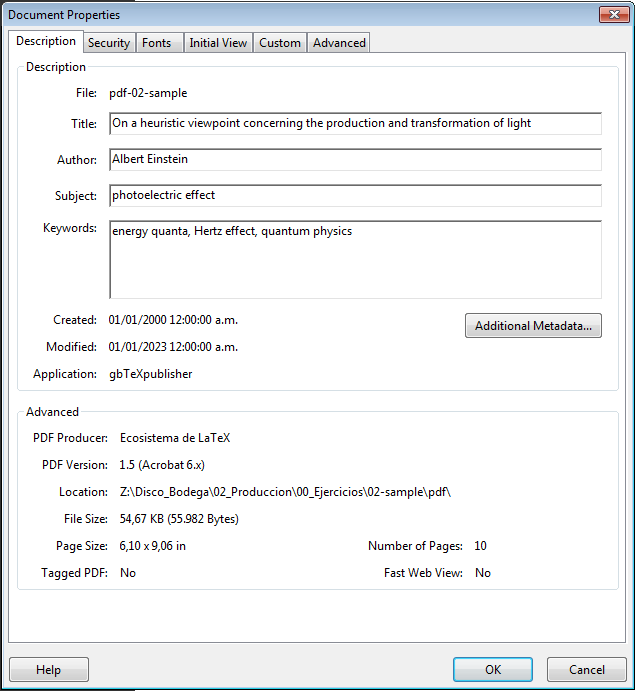
El tratamiento de los metadatos en los libros es muy diferente al que tiene en los artículos de revistas, mientras que en el primer caso si faltan la compilación no da error, en el segundo sí. La ausencia de los datos desperdicia la posibilidad de inyectar estos en los diferentes formatos de salida, por ejemplo, la salida a PDF tiene soporte para XMP, muchos indexadores toman los metadatos leyéndolos del PDF, no de la etiqueta asociada en el repositorio.
Las siguientes capturas muestran que metadatos son leídos en el PDF por los indexadores.
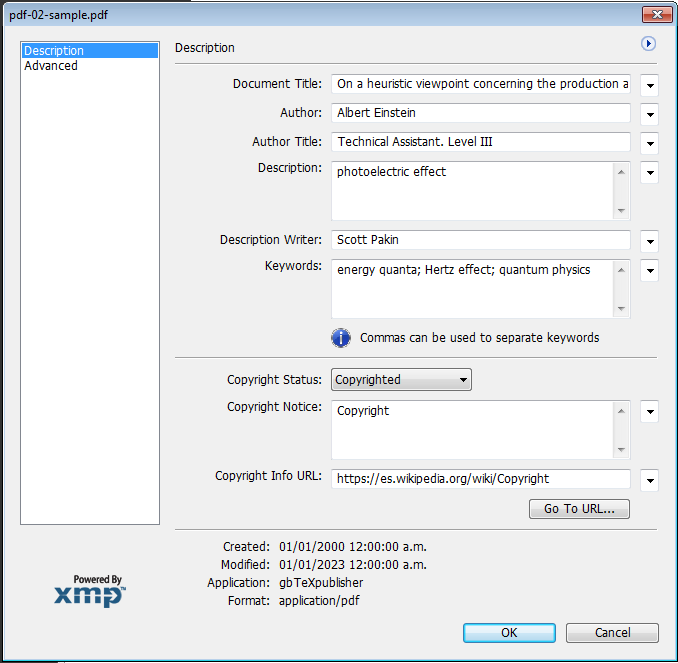
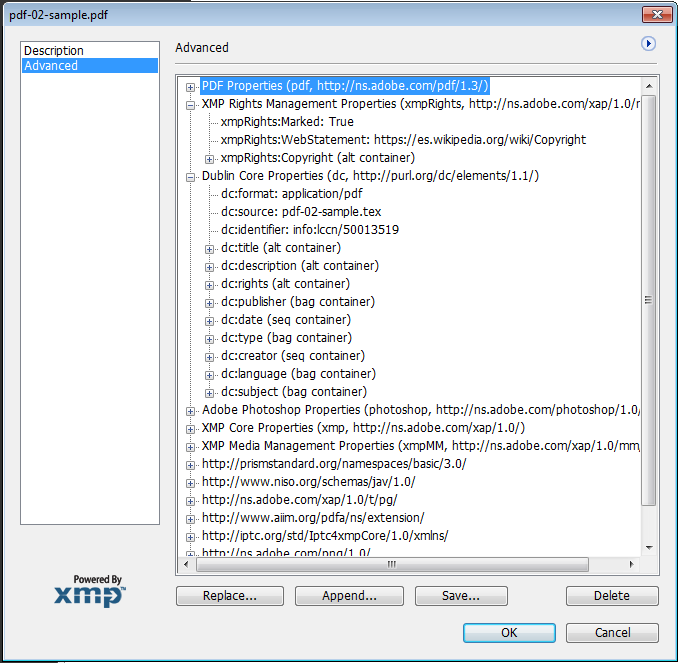
Los metadatos específicos de los autores y las colecciones se trabajan desde otras tablas de la base de datos para evitar la redundancia. El siguiente video es una muestra parcial de todo lo explicado anteriormente.
Git local y remoto como copia de seguridad temporal
Hace un tiempo (largo) vi una imagen en la red linkedin que a simple vista (antes de leer el artículo) pensé que era un meme,11 en la misma había muchos archivos MS Word, nombrados: versión final, versión final final, esta es la última versión, ahora sí la última; y así muchas copias de un word con todos los nombres que se pudieran imaginar, la imagen buscaba encontrar quiénes se identificaban con la misma.
gbTeXpublisher trabaja con Git como sistema de control de versiones, este es ampliamente utilizado para el seguimiento de cambios. Fue creado por Linus Torvalds en 2005, es una herramienta poderosa, flexible y fundamental para el trabajo en equipo. Puede llevar algo de tiempo acostumbrarse –a su lógica de uso–, pero una vez aprendidos sus conceptos se vuelve esencial para trabajar de manera sólida y segura, aún así, en gbTeXpublisher el acto de hacer las instantáneas de respaldo quedo simplificado al punto de un solo click de mouse.
Si se desea trabajar solo en modo local no es necesario tener una cuenta en GitLab.
En el siguiente video, muestro como es el uso diario.
Controlando los tiempos y las cargas de trabajo
Aún trabajando solo, a veces es aconsejable saber cuanto tiempo y esfuerzo (léase dinero) le hemos asignado a un trabajo, la capacidad de Kanban en GitLab es ideal para esto.
Kanban, cuyo significado es letrero o tarjeta en japonés, es un sistema de información que controla de modo armónico la fabricación de los productos necesarios en la cantidad y tiempo necesarios en cada uno de los procesos que tienen lugar tanto en el interior de la fábrica, como entre distintas empresas (Wikipedia).
Ni que decir, si el trabajo es en equipo (no confundir trabajar en equipo con trabajar en red), donde todos acceden a los mismos archivos.
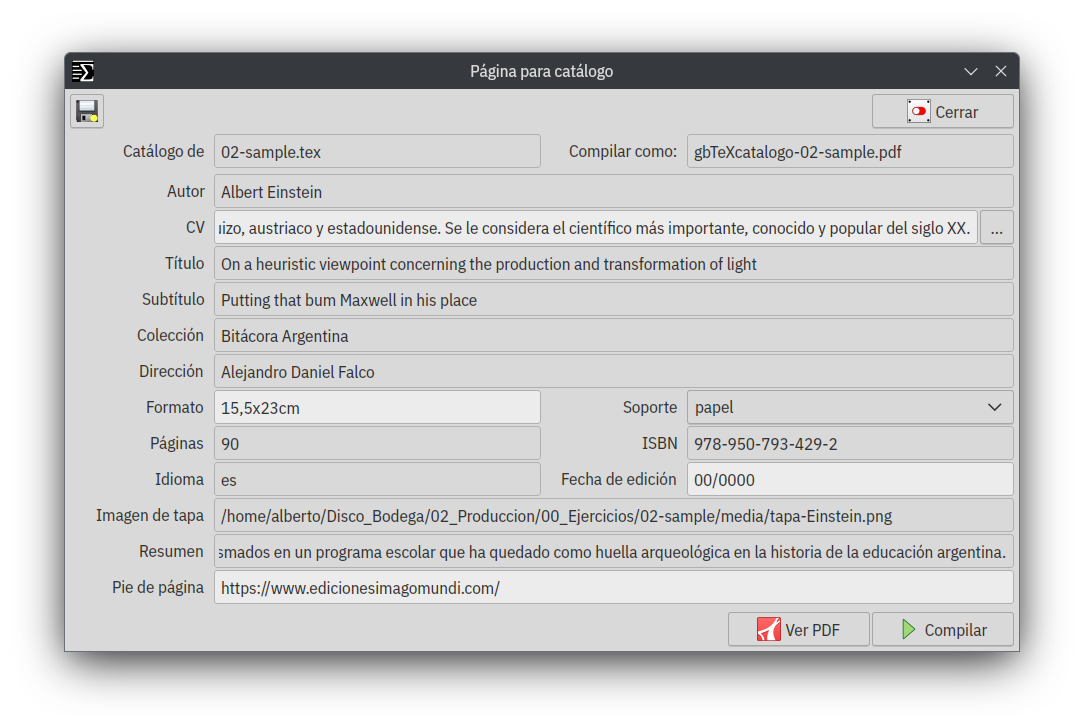
Catálogo automatizado
Fue imperativo abordar de manera ágil y eficaz (y segura) la cuestión del catálogo en formato PDF. La construcción se realiza mediante una plantilla predeterminada, extrayendo los datos necesarios de los metadatos. Solo restan dos datos por añadir manualmente: el autor y el currículum vitae (los motivos se detallan en el video). En perspectiva, aspiro a realizar modificaciones que permitan trabajar con diversas plantillas, posibilitando así la creación de diseños variados. El video siguiente ilustra el proceso de utilización.
El PDF que obtengo lo llevo a un directorio en donde se encuentran todas las páginas de los diferentes libros y un script hace el trabajo de costura concatenando todos los archivos en uno solo más una tapa.
Obteniendo estadísticas
Estudiar cómo a sido editado un libro o artículo a través de los resultados estadísticos de su interior es lo que permite este módulo, básicamente el contador rastrilla todo el proyecto y lo informa en diferentes planos.
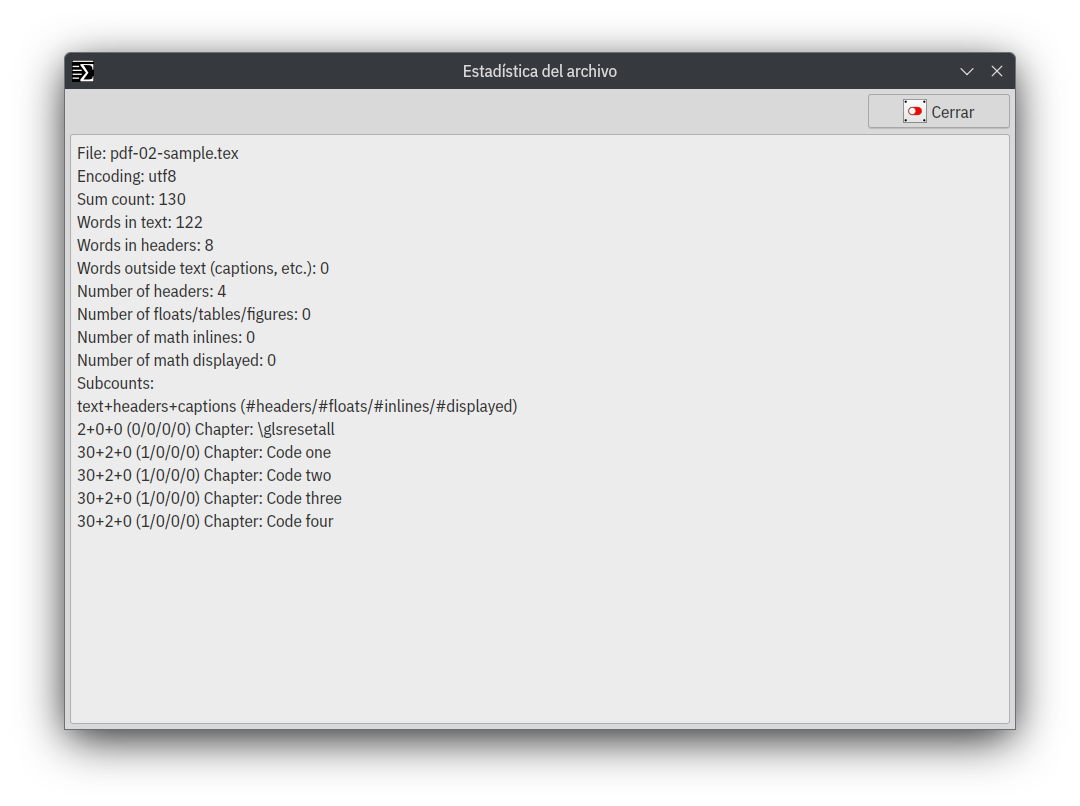
Control de errores desde el logfile
En LaTeX existen diferentes tipos de errores, los voy a agrupar en 2 categorias: suaves y duros, los primeros no afectan la generación de la salida, los segundos directamente abortan el proceso de compilación. Por ello es que LaTeX (como todos los lenguajes de programación) provee un archivo de salida que registra todo el proceso de compilación, ya que en caso de ser necesario se lo puede consultar para empezar a indagar por donde vienen los conflictos.
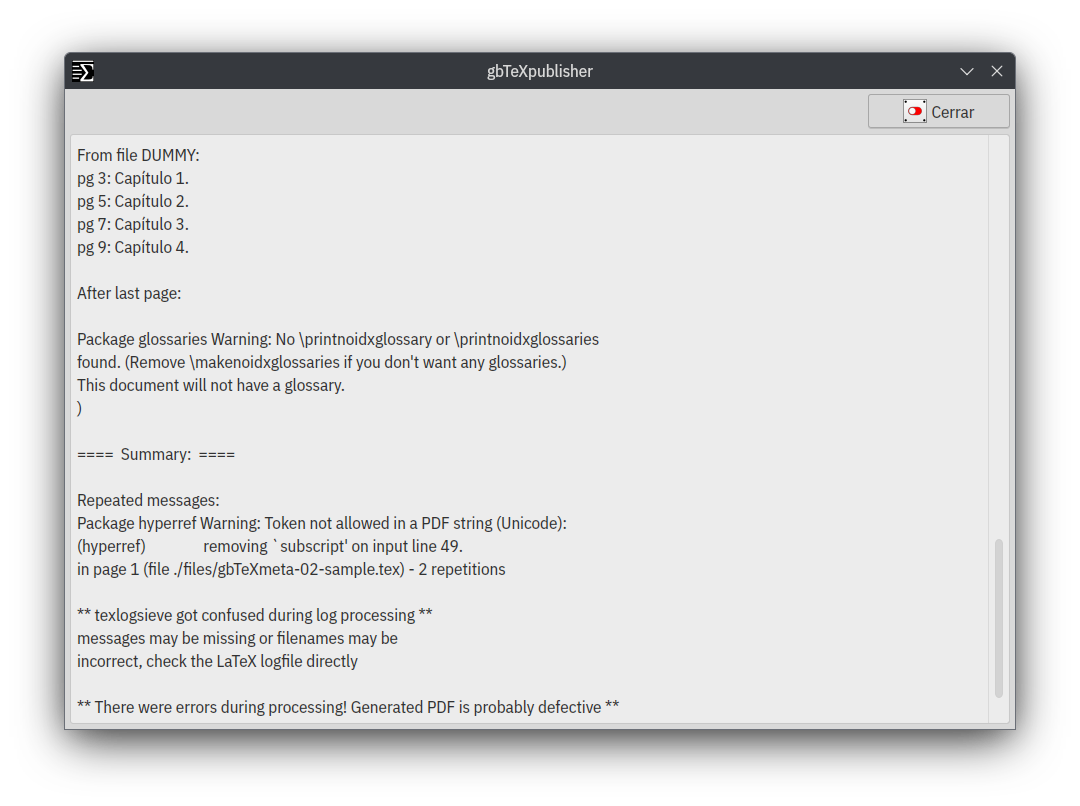
Copia de seguridad del trabajo terminado
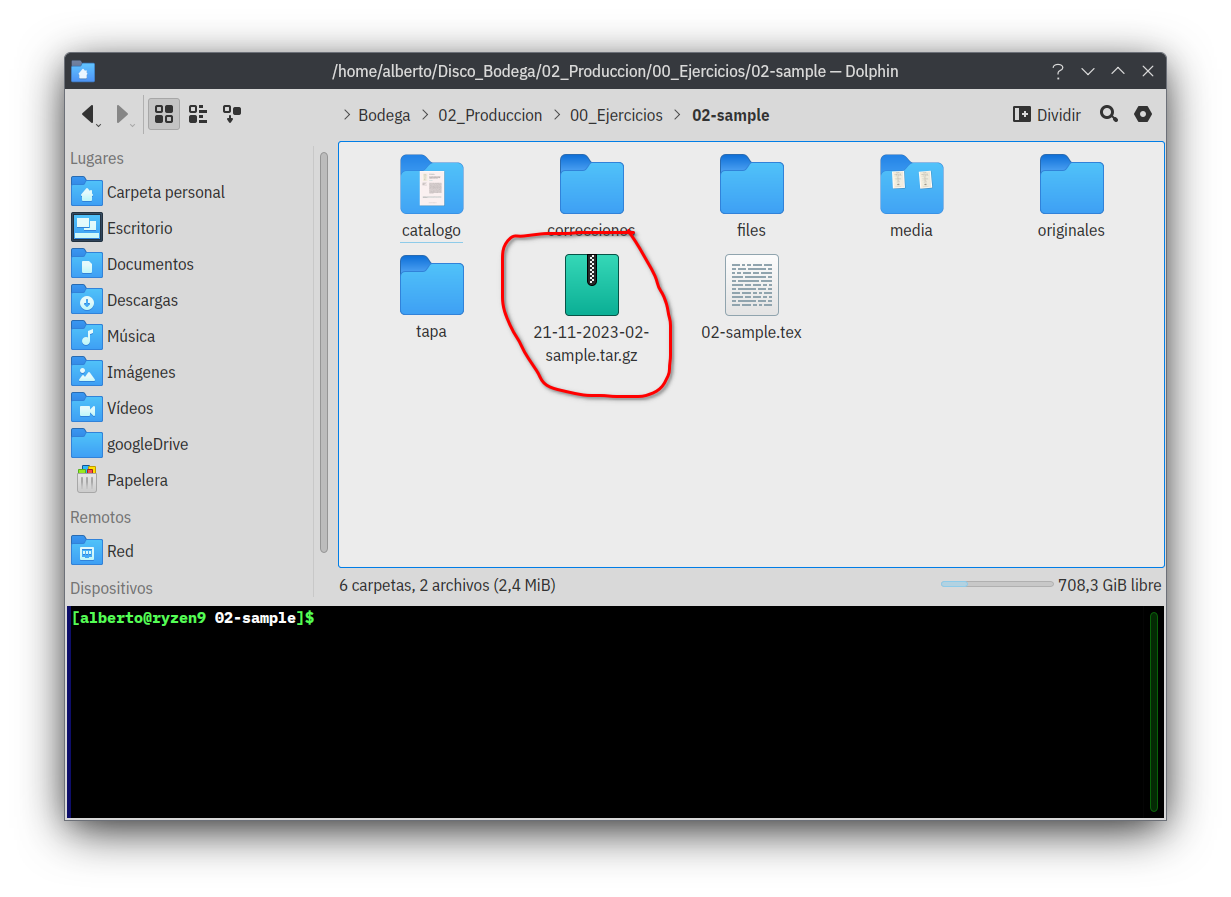
Llegado a este punto, el trabajo está terminado, el libro impreso, la versión electrónica subida al repositorio, etcétera. Ha llegado el momento de guardar todo en un depósito de respaldo, yo personalmente utilizo Mega, su relación costo/beneficio para este menester es la mejor (hay más opciones, por supuesto), también tengo un abono en Google para expandir mi cuota en Drive, pero lo utilizo para otras cosas. El menú Comprimir directorio para respaldo, básicamente lo que hace es una copia comprimiendo todo en formato .tar.gz, la imagen a continuación lo dice todo. Después solo resta llevar ese archivo al repositorio de respaldo.
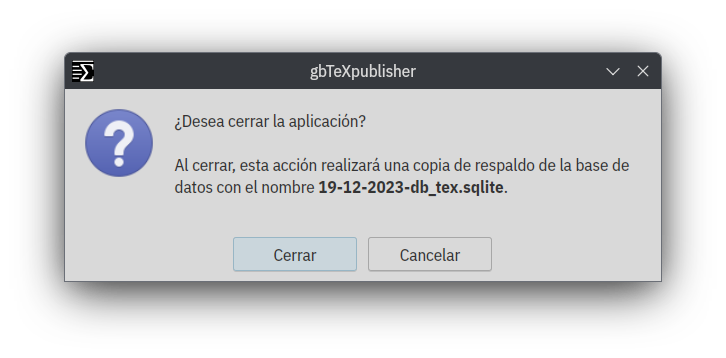
Copia de respaldo de la base de datos
Esta constituye una de las primeras retroalimentaciones que recibí de aquellos que están probando gbTeXpublisher. No me había percatado de incluir una función para respaldar la base de datos. Ahora, cada vez que se cierra la aplicación, se genera automáticamente una copia de respaldo en el directorio .respaldogbTeX. El nombre del archivo se modifica al agregar la fecha, lo que implica que las copias del mismo día se sobrescriben. No hay restricciones en cuanto a la cantidad de copias respaldadas; cada usuario puede decidir cuántas desea conservar.
Comentario final
Para explicitar lo obvio, no creo que los editores de libros deban tener conocimientos de programación de manera obligatoria. La función principal de un editor de libros o revistas es y seguirá siendo trabajar con el contenido, asegurándose de que sea claro y coherente con una estructura lógica y gramatical. Sin embargo, vivimos en un mundo en donde la tecnología desempeña un papel clave en la producción y distribución de contenidos, y esto incluye a los libros y las revistas.
En la situación actual, contar con conocimientos en informática, incluso a un nivel básico, resulta altamente beneficioso para un editor. Esto se debe a la creciente prevalencia de la publicación digital y la distribución en línea. La comprensión de conceptos técnicos relacionados con formatos de archivos, condicionales, expresiones regulares, seguridad, entre otros, será de gran utilidad para aquellos que se desempeñan en la industria editorial.
No tengo dudas de que el ámbito editorial en el que me desenvuelvo, específicamente la edición científica, requiere una transformación significativa en su modelo de producción. Esta evolución es crucial para asegurar su sostenibilidad a lo largo del tiempo, permitiendo el procesamiento y la difusión de contenidos sin restricciones temporales. La calidad de las fuentes de información generadas está directamente influenciada por el método seleccionado para la producción editorial.
Es evidente que la complejidad interdisciplinaria inherente a esta profesión, con la participación de diversos conocimientos, desempeña un papel fundamental en el campo de la producción del conocimiento.
Matthew Carter en una exposición en el 2014 lo planteó en términos muy simples:
La pregunta es, ¿una restricción obliga a un compromiso? Aceptando una restricción, ¿estás trabajando a un nivel inferior? (…). La distinción entre una restricción y un compromiso es, obviamente, muy sutil, pero es muy central en mi actitud hacia el trabajo (min. 4:57).
Es oportuno aclarar que, así como gbTeXpublisher puede tener modificaciones en el futuro, este artículo también puede ser modificado a medida que pasa el tiempo. Además, es importante señalar que dado que gbTeXpublisher está distribuido bajo la Licencia Pública General de GNU (GPL), este se proporciona tal cual y sin garantías. La licencia GPL no otorga garantías explícitas y se insta a los usuarios a consultar los términos de la licencia para comprender completamente sus derechos y responsabilidades.
Gambas y solo GNU Linux
No soy programador, me identifico plenamente como editor con una fuerte formación en artes gráficas (tuve taller de preprensa e imprenta durante 15 años), así que mis conocimientos informáticos son en base a mucha lectura y práctica. Estuve durante mucho tiempo lidiando con Python, Lazarus y Ruby, reconozco ventajas en todos estos lenguajes, pero mi reflexión en la búsqueda de una solución informática consideró primordialmente el balance entre: facilidad de uso y productividad; el resultado me llevo a encarar gbTeXpublisher con Gambas.
Gambas es un lenguaje de programación libre derivado de BASIC (de ahí que Gambas quiere decir Gambas Almost Means Basic). Se distribuye con licencia GNU GPL. Cabe destacar que presenta ciertas similitudes con Java, ya que para la ejecución de cualquier aplicación, se requiere un intérprete previamente instalado (Gambas Runtime) que entienda el bytecode de las aplicaciones desarrolladas y lo convierta en código ejecutable por el computador (wikipedia).
Aunque las razones que me llevaron a elegir trabajar exclusivamente con GNU Linux son personales, reconozco que pueden suscitar preguntas. A continuación, expongo cuáles fueron los factores más relevantes que influyeron en mi elección:
- Utilizo GNU Linux desde hace 30 años.12
- Solvento mis gastos trabajando como editor, no programando.
- Creo que el conocimiento es una construcción colectiva.
- Gambas es un RAD, es rápido, potente (Benchmarks) y muy fácil de aprender.
Algunas aclaraciones sobre mi plataforma de trabajo
Por motivos que no hacen a este artículo y sabiendo que todas las distribuciones de GNU Linux tienen diferencias en las librerías gráficas, voy a mostrar cual son las características gráficas del equipo con el que desarrollo y trabajo a diario utilizando gbTeXpublisher, cualquier persona que este intentando utilizar la aplicación y tenga problemas con los elementos de la interfaz gráfica me puede contactar indicando que distribución utiliza, con cuál librería gráfica y entorno de escritorio y veré de hacer pruebas de control.

-
De Bono, Edward (1967). New Think: The Use of Lateral thinking, Avon Books. ↩︎
-
Un lenguaje de marcas es un sistema de codificación que utiliza etiquetas o marcas para definir y estructurar el contenido de un documento. A diferencia de los lenguajes de programación tradicionales, los lenguajes de marcas no se centran en instrucciones para la ejecución de programas, sino en la presentación y estructuración de datos. ↩︎
-
Los metadatos desempeñan un papel crucial en el contexto de la ciencia abierta, ya que facilitan la gestión, el descubrimiento y el acceso a la información científica. Veamos algunas razones por las cuales los metadatos son importantes: (1) Descubrimiento de investigación: permiten una descripción detallada de los conjuntos de datos, artículos y otros recursos de investigación. Esto facilita su descubrimiento por parte de otros investigadores, ayudando a ampliar la visibilidad de la investigación. (2) Interoperabilidad: al utilizar estándares de metadatos comunes, se mejora la interoperabilidad entre diferentes plataformas y sistemas. Esto facilita la integración de datos y la colaboración entre distintas iniciativas de ciencia abierta. (3) Reproducibilidad: bien definidos contribuyen a la reproducibilidad de la investigación. Proporcionan información detallada sobre cómo se recopilaron, procesaron y analizaron los datos, lo que permite a otros investigadores replicar o verificar los resultados. (4) Atribución y citación: pueden contener información sobre los autores, afiliaciones, fuentes de financiamiento y otros detalles relevantes. Esto facilita la atribución adecuada de la investigación y el seguimiento de las contribuciones individuales. (5) Gestión de Datos: son esenciales para la gestión eficiente de datos a lo largo de su ciclo de vida. Ayudan a organizar y describir los conjuntos de datos, lo que facilita su almacenamiento, acceso y preservación a largo plazo. (6) Cumplimiento de políticas y normativas: son útiles para cumplir con políticas y normativas relacionadas con la transparencia y la apertura de la investigación. Proporcionan detalles sobre la conformidad con estándares éticos, licencias de datos y otros requisitos institucionales. (7) Mejora de la calidad: la disponibilidad de metadatos precisos y completos contribuye a la mejora de la calidad de la investigación. Facilitan la revisión por pares y la evaluación de la validez y confiabilidad de los datos. (8) Facilitación del Acceso Abierto: pueden incluir información sobre la disponibilidad y los términos de acceso a los recursos de investigación. Esto es fundamental para garantizar un acceso abierto y equitativo a la información científica. En resumen, los metadatos son herramientas fundamentales para la gestión eficiente, el descubrimiento y la utilización de la investigación en el contexto de la ciencia abierta. Contribuyen a la transparencia, la colaboración y la maximización del impacto de la investigación en la comunidad científica y la sociedad en general. ↩︎
-
Puede ser cualquier valor de la estructura: título, referencia, fórmula, etcétera. ↩︎
-
Furtado, José Afonso (2014). La edición de libros y la gestión estratégica, Córdoba: EDUVIM. ↩︎
-
Una traducción posible de homeoarchy sería: omisión accidental de una línea de texto durante la lectura, debido a similitudes en su contenido inicial. ↩︎
-
Hacer un listado de todo lo que circula en Internet sería un sinsentido, dejo aquí este que además de gratuito está bien estructurado https://www.learnlatex.org/es/. ↩︎
-
CTAN (Comprehensive TeX Archive Network) es el lugar central para todo tipo de material relacionado con TeX. CTAN cuenta actualmente (06/12/2023) con 6521 paquetes. Con 2957 contribuyentes trabajando en ello. La mayoría de los paquetes son gratuitos y se pueden descargar y utilizar de inmediato. ↩︎
-
En este video (https://www.youtube.com/watch?v=h7gsqTQq8VU) de Juan Macías –un excelente ortotipógrafo español– se puede observar todo el potencial que hay en el uso de Lua con LaTeX. ↩︎
-
En programación y lógica, una sentencia condicional se utiliza para realizar acciones diferentes según si una condición es verdadera o falsa. Se basa en el concepto de «si-entonces» y permite que un programa tome decisiones dinámicamente durante su ejecución. ↩︎
-
Un meme es un tipo de contenido que consta de varios elementos (por ejemplo, una imagen y un texto) relacionados en una misma unidad significante, para representar una idea, concepto, opinión o situación. Generalmente, su tono es humorístico, irónico o satírico y se crean para transmitir un mensaje o una idea de manera rápida y efectiva. ↩︎
-
En el año 1993 fundé SaveAs… un taller de preimpresión en el que tenía 4 servidores con Debian. ↩︎